How to build and integrate an AI chatbot in a webpage

What are we building?
In this post, we are going to build an AI chatbot to answer questions about your career’s journey, using Megamind’s Chatbot APIs via Postman. For the purpose of this post, I am going to use my career’s data to demostrate this process, but you must use your data to get questions on your career answered.
What value does CareerBot offer?
It serves as your online perosnal representative to answer questions about your professional career and achivements to recruiters, investors, employees, clients and any who needs this know this about you.
In this post, the final CareerBot will able to answer questions like below, and many more like these around my career.
- What project has made Vishesh proud and what were the challenges he faced?
- What organizations has Vishesh worked for and where were they located?
- What programming languages and tech stacks does Vishesh have expertise in?
- What is Vishesh Gupta’s email address?
Lets start!
Step-1: Get your api key
Use get_api_key api to get your megamind api-key. You need to pass an email address where you will receive the api-key. For e.g.:
{
"email":"abc@sample.xyz"
}
Note: It is neccessary step, without api key other apis won’t work
Step-2: Create a knowlege base from which the bot will answer the questions
A Chatbot’s knowledge base is a context, whose ID called context_id represents the information and data that this chatbot refers to, to answer any question asked to it.
Step-2.1: Create a new knowledge base
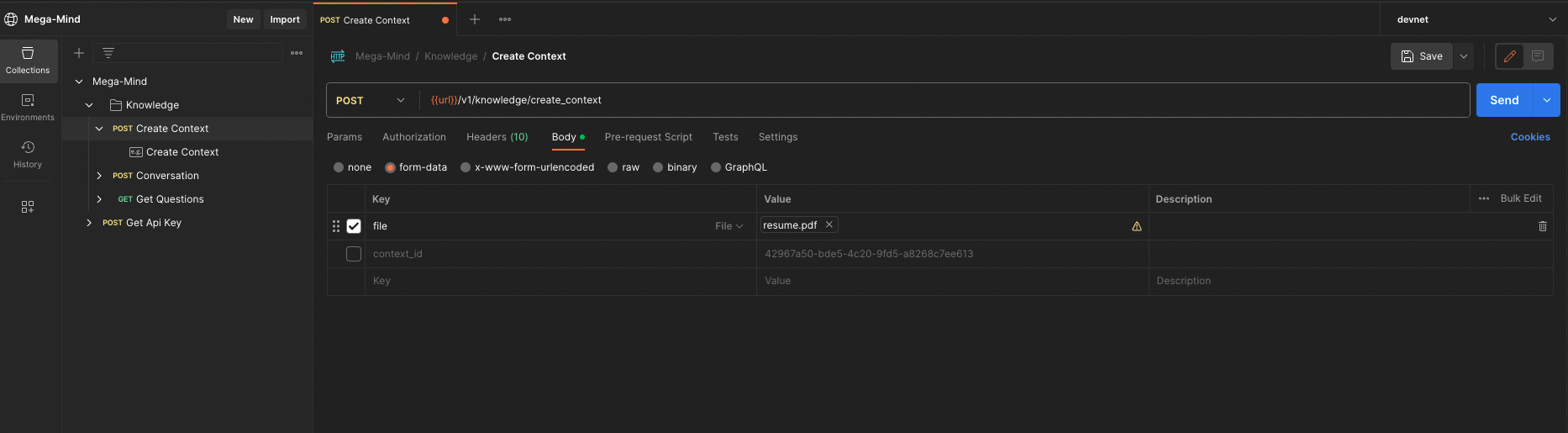
Use the create_context api to create a new context by making an HTTP POST request to the specified URL. The request should be of form-data type and include a file and an optional context_id parameter.
Set authorisation Key in request header:
In the request header field X-Api-Key enter the api-key value that you received in your email.
Request Body:
- file (file): The file containing text data, the data in this file will be used to answer users’ questions. Currently, only supports .pdf, .txt, .csv file formats.
resume.pdf
My resume’s PDF file
- context_id (text): The knowledge context ID that this data is added to. Leave this empty or omit the context_id parameter from the request body. This results in the creation of a new knowledge context, with the data present in the file. The newly created knowledge context’s ID is returned in the response.
Response:
Upon a successful request, the response will include the newly created context_id in the result object. Like below:
{
"result": {
"context_id": "77df6825-44fb-4f5a-95dc-6c101ace42cf"
}
}
Step-2.2: Add more files to update the knowledge base with more information about you.
I want to give more data about me so that the bot can answer questions well.
In each request only 1 file can be uploaded hence I will make 2 more requests to the same api but this time we will also send the context_id` returned in the last request’s response in these requests.

Request-1:
- context_id (text):
77df6825-44fb-4f5a-95dc-6c101ace42cf - file:
languages.txt
Languages and Tech stacks that Vishesh has expertise in: Programming Languages: Golang, JavaScript, Typescript, C/C++, Java, C#, Python, Solidity. Development Frameworks: NodeJS, Express, ReactJS, Spring, Hibernate, JPA, Google Guice, NestJs, Angular, Ethereum, Solana, Polygon, REST Apis, OpenAi, ElevenLabs, Twitter APIs, QuickNode, puppeteer, HuggingFace. Data and deployment Systems: MongoDB, PostgreSQL, RabbitMQ, AWS, Redis, Docker, GitHub Actions, CI/CD, Nginx.
Request-2:
- context_id (text):
77df6825-44fb-4f5a-95dc-6c101ace42cf - file:
cover_letters.txt
A document on Vishesh's work throughout his career. Vishesh founded a fintech Startup called Bondgeek, where we were trying to build a bond investment platform for retail users. In our research, we came across Zamp and were impressed by their businesses-first approach towards the market. About Vishesh, he is an experienced software engineer, who is very strong in Backend and can handle full stack development as well. He have worked for multiple startups in key positions of Staff engineer, CTO, and senior engineer. He loves writing code and building software. In his 11 years of journey, he have mentored a lot of junior and senior engineers to build, maintain and evolve technology and code bases across organizations like Ubisoft, Amazon, Playment (yc 2017), Shyft.to. Apart from jobs, he has built free-to-use tools as well. Out of which the most recent one is: SpotAI, an AI-powered browsing assistant to reveal information on any webpage quickly. Anyone interested can try it out here: https://chromewebstore.google.com/detail/spot-ai/klecemighfnommaecegoefedcdappbep. ---------------------- A project where Vishesh had to closely collaborate with non-engineering peers. * He was working as a tools programmer in Ubisoft, where my job was to build and improve the tools that artists, and level designers used to build assets for the games. His way of working with them was he would walk upto them and just observe them using the internal tools that were critical to their job. After a while they would even forget that he is sitting there observing their workflow. He would do this 1 day in every sprint. This exercise helped him a lot to identify gaps in their efficiency, what is about the tools that annoys them, and what is that that can be completely removed to reduce their workload. He would come up with features and improvements that can be done in our tools to improve their on-job experience. After validating if the proposed features and estimating the resource needed to build them, he would pick up the top priority items, build and ship them, and then again go back to observing them and taking feedback. This lead to a new relationship between development team and art teams as they could come up to us if they faced bottlenecks, and give feedback on things that can be improved. With this simple exercise we were able to build really useful and efficient game tools, that were later adopted to be used in different games, as well. A Project that makes Vishesh Proud, and why is he proud of it? While working with Playment (YC 2017), a AI/ML data annotations company, as lead engineer, He worked on making the entire system fault tolerant. This system comprised of multiple micro-services that were all inter-connected via rest-apis and message broker queues. Due to normal system faults like, server-restarts, deployment, or bad request or any other system fault, the data would get stuck in the data pipelines, resulting in PMs missing submission deadlines, and company loosing client's trust and business. We had an on-call function in our team mainly because of this problem, and since we were providing support to clients in US regions, the on-call dev often had to get up in the middle of the night to fix it. A data got stuck in the data pipeline when its state in the database became inconsistent with respect to the system rules. The reason for this inconsistency was our database operations were not transactional, i.e. if in a request flow there are 5 write operations (database or sending messages in queue or post/put API request to other micro-services), then all 5 were triggered in isolation. Therefore, if any error occurred after let's say 3rd write operation, then the next 2 wont happen leading to data in inconsistent state. So, the requirement here was either all 5 should happen if not then none should happen. Handling the database writes was easy as all the write operations had to be moved in a transaction object. But handling the messages sent to queues and api calls to other services such that every data item is processed only once was tricky. For this he used idempotency principals for APIs, and wrote a new rabbitmq queue boot-loader that used retry mechanisms and new application receiver interface to hanlde idempotent messages, which allowed an already processed message to be not processed again. It was a 3 month long effort, and once he was done, there were 0 data stuck issues. And to fix it he had pushed 12k lines of code in the PR, that no application developer even noticed as it was all at a very low abstraction layer, near to our application's core functions and boot-loaders. The code was properly tested. Most critical components of this PR were done using TDD. And overall test coverage for this PR was around 60%. After this change PMs could commit the deadlines with confidence and were able to get a lot more projects done. And we also ended up removing the on-call dev function after 2 months of this running in production. Vishesh's remote work experience and his take on benefits and challenges involved in a remote environment. He has been working in remote setting since past 4 years now. In these 4 years, he has collaborated with people in multiple timezones. In these 4 years he has build 1 blockchain startup that had dev teams in India and client spread across the globe. He also participated in multiple hackathons where his team mates were in Nigeria, Amsterdam, US and Japan. And since past 6 months, he am building Gen-AI tools remotely in collaboration with friends in Japan and Nothern-India. Overall, he love working remotely, for few reaons: - He don't waste any time in commute, he spend these saved hours on my mental and physical fitness. - Working async also leads to greater productivity, as he get more time to do focus work. And when coming for sync-ups, he is really on point, and things that matter are really clear. According to him one challenge that sometimes can be is: - Making a strong human bond with peers and clients. Like when in person one can learn a lot by just observing how people work, that learning gets missed here. And personally, he like to know people around me on a deeper level and build relationships that we can cherish outside work as well. - Also, one challenge that he faced when working with junior engineers was to help them up-skill fast. Vishesh's ability to learn new programming languages and technology stacks: Before joining Playment in 2018 he had not worked with Golang either. But he learned it on the job and delivered his first major feature within 3 months of joining the team as their first Senior Engineer. Later, he co-founded a blockchain infrastructure startup where we built on Js/Typescript stack, and at the time of starting he had probably written only 500 lines of code in JS, but again he was quickly able to learn it and build product features and get initial traction that helped us secure funding for the product, also was able to find anti-patterns in the code written by junior programmers. --------------------------------- Another example of an intricate system engineered by Vishesh: Context: Implement project-level queues in our data labeling processing pipelines, to prevent the noisy neighbor problem. System Design: We had a workflow consisting of multiple interconnected steps. The output of each step could be the input to the next step. The output and input entities were a particular JSON called FLU, which represented a single unit of data in the system. Each step of the workflow was an independent service, accepting input via a single Rabbitmq queue. There would be multiple projects' Flus getting processed at each step. One of these steps was a Python script step, which would do certain transformations in the raw JSON for every Flu that came in this step. The processing time was directly proportional to the size of the flu. There can be multiple Python steps in a single workflow. Example: Let's suppose there is 2 projects A, and B. Average Flu size in A is 10kb and the average flu size in B is 10 Mb. The flus of project A will take significantly less time to get processed at the Python Step, and move to the next step. System Usage: Every Project Manager(PM) will create a workflow do process flus of a project. Since each project had a different requirement, therefore workflow, a combination on many steps, had to created differently for each project. Each project would have a submission deadline, which was the most important KPI for PM team. Problem: When Flus from different projects entered the python step queue, they would start getting processed immediately and our python service could handle only 8 concurrent flu processings. This is where the problem lay, if a lot of Flus from project B reach the the python step first, and project A flus arrive later, then the all other projects' Flus will be stalled as python service would be busy processing flus of project B. This resulted in starvation of project Flus. Solution: In the service which sent the Flus to python service, we implemented project-level queues, i.e. now each had its own dedicated Flu at each step of the workflow. We re-wrote the queue receiver to implement a round-robin mechanism to reach data from each queue. On reading data from a queue we checked if the python service has maximum number of allowed Flus per project already under processing, then the receiver will skip this project queue and move to the next one, only to revisit it later after 1 complete cycle. Why is he proud of this project? - Wrote a lot of low level code, like new queue bootloader, new queue receiver for the application - It was backward compatible, no migration was needed to put this in production. - Every step, had a choice to implement the input queue the old way or use project level queues. - No new interface changes for Application developers. - completely unit tested. Describe the most recent CI/CD process you've used - how a code change propagated to production? Were you involved in the development of the CI/CD process? I setup github actions that does 2 things: 1. on pushing the code to main branch, it checks the sanity of the code, if it compiles alright and runs the unit tests. 2. on creating a release it deploys the code in the aws ec2 instance. We work on our individual feature branches, and create a pr that is to be merged in the main branch after the code review. Once merged the github actions flow gets triggered. On creating a release the actual code gets deployed in the production ec2 instace. Yes, I setup this CI/CD flow.
By now, you have successfully created your knowledge context. Good going!
Now on to last and final Step. Yay.
Step-3: Integrate your CareerBot in your website
- Add the below code in the body element of your webpage’s html code:
<script> window.__EMBEDDED_DATA__ = { client: { contextId: "<YOUR_CONTEXT_ID>", authKey: "<YOUR_API_KEY>" }, customData: { botName: `<NAME_OR_YOUR_BOT(Optional)>` }, elementId: 'root', }; </script> <script src="https://embeddable-chatbot.s3.ap-south-1.amazonaws.com/index_b2.js"></script>Explanation:
elementId: The #id of any html element where you want to render the bot. If left empty, the script attempts to render the bot in therootelement, if not present then bot will not be rendered.authKey: The api key that you received in your emailId, inStep-1.contextId: The knowledge context id that you received from the api request inStep-2-1.botName: The name of the bot. In my case it isVishesh's Agent. You can leave it empty or give it a value.
Result
Finally, we are done! Congratulations.
I deployed my CareerBot by embedding the above <script> tags in my blog’s about page, here:
On reloading the html file you should also see the bot, click and ask questions to it, and have fun interacting with your Online Avatar.
Hope you had fun building this.
Let me know if you get stuck somewhere, or have feedback, also would love to see your bots as well. Please feel free to write to me vgvishesh2018@gmail.com
Keep Building!!